------------------------------------------
Term paper
-group member 정보는 email로 송부, member간 CP 은 조원들끼리 공유
-주중/주말 간 메신저를 통한 면담 실시
-term paper 대상
--자료의 종류
===상관없음
--사용 방법론
===경제학 범주 내에서 가능한만큼
Ex)특정 이벤트(사스,에볼라,코로나 등)이 시장에 미치는 영향은 예측이 가능한가
----No 예측은 불가능하다, 시장은 예측의 영역이 아닌 대응의 영역이다
----시장은 효율성과 비 효율성의 중간 지점에서 동작한다
To-do
1)논지의 설정 –시장에서 xxx현상을 예측하겟다
2)자료의 download
3)자료 정리
4)상관관계 분석
-------------------------------------------------------
왜 사용할까?
– avoid loop = loop 상황을 피하는게 전체 메모리 사용에 좋기 때문
- 컴퓨터 사이언스와 다르게 쉬운 방법으로 데이터를 가지고 원하는 논리를 검증하기 위해
Pandas의 group by = 해당 data set에서 기준을 잡고 해당 기준 안에서 추가 연산을 진행
Group by의 aggregate , filter , transform 사용
예시를 위해 seaborn 에서 planets 데이터를 호출한다
import numpy as np
import pandas as pd
import seaborn as sns
planets = sns.load_dataset('planets')
planets.shape
== (1035, 6) - 1035건의 데이터와 6개의 column이 있음
planets.head(10)

해당 data의 기본 통계분석
planets.dropna().describe()
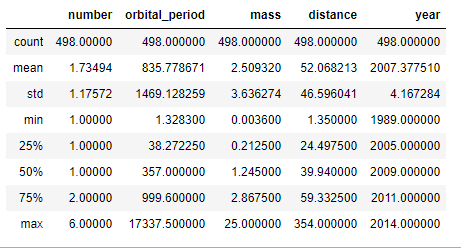
해당 data의 item 의 수를 카운트
planets.count()

##planet 데이터의 min(), max(), mean(), std(), var(), mad()를 확인한다 (planets.min())
##Column 정보 확인
planets.columns
= Index(['method', 'number', 'orbital_period', 'mass', 'distance', 'year'], dtype='object')
댓글 없음:
댓글 쓰기