=통계학의 “기술”은 Technique 이 아닌 Descriptive 로 해석과 요약에 중점을 둔다
=통계, 데이터를 설명하는 통계학의 한 분야
기초 통계량
=표본 평균, 분산, 표준편차, 수치 요약, 최빈값, 중앙값
R상에서 실습 코드
| Code |
| #기초통계량 실습코드드 mean (1:4) #평균 var (1:4) #표본 분산 sd (1:4) #표준 편차 summary(1:4) |
 |
EuStockMarkets 의 기술 코딩
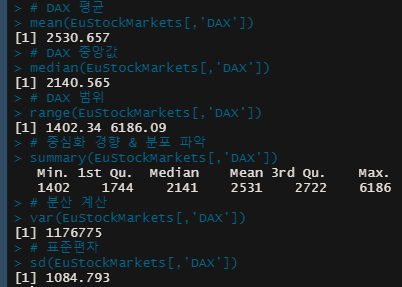
| # data set 사용 선언 data("EuStockMarkets") # data set structure 파악 (row , column) dim(EuStockMarkets) # data set 호출로 전체 데이터 파악 EuStockMarkets #전체 data 에서 'DAX' 변수에 해당하는 데이터 출력 EuStockMarkets[,'DAX'] summary(EuStockMarkets) # DAX 평균 mean(EuStockMarkets[,'DAX']) # DAX 중앙값 median(EuStockMarkets[,'DAX']) # DAX 범위 range(EuStockMarkets[,'DAX']) # 중심화 경향 & 분포 파악 summary(EuStockMarkets[,'DAX']) # 분산 계산 var(EuStockMarkets[,'DAX']) # 표준편차 sd(EuStockMarkets[,'DAX']) |
 |
확률(probability)
=確率 – 굳을 확, 비율 률
=어떤 결정 등을 굳힐 비율
통계에서 확률
=동일 조건에서 같은 실험을 N번 반복
=사건 a가 모두 몇 회 발생 했는지 조사 = n
=사건 a가 발생할 확률

=주사위에서 모든 눈이 나올 확률은 시행 횟수 N이 많아지면 비슷해진다
확률 공리 – 공리적 확률
=
 는 0과 1 사이의 값을 갖고
는 0과 1 사이의 값을 갖고
확률변수의 값의 종류
| 이산형 |
확률 질량 함수  |
| 연속형 |
확률 밀도 함수  |
베르누이 실행
=P의 확률로 원하는 결과가 나타났을 때 ‘성공’으로 1-P의 확률로 그렇지 않은 결과가 나타났을때 ‘실패’로 하는 두가지 결과가 나타나는 확률 실험
이항분포
=성공 확률이 P로 동일한 베르누이 시행을 n번 반복해서 실험하는 경루
==실험이 n번 반복 되도 성공 확률 p는 변하지 않고 동일
==이항 분포의 모수
===n – 시행의 횟수
===p – 성공의 확률
정규분포
=종 모양 형태
=평균을 중심으로 좌우 대칭
=평균 중심에 모여있다 양끝에 적용
=표준 편차가 작으면 종이 예리하게 좁아진다
=표준 편차가 크면 종이 평평해진다

표준 정규분포
=평균이 0이고 표준 편차가 1인 정규 분포


댓글 없음:
댓글 쓰기