이미지의 정의
|
이미지는 높이 * 너비 * 채널로 이루어진 3차원 tensor이다 |
|
흑백 이미지는 채널수가 1이며 각 pixel 은 0~255 사이의 값을 가진다 |
|
높이 28 너비 28인 “컬러” 이미지의 tensor는 28 * 28 * 3 이다 (마지막이 채널값이 들어간다) |
|
이미지는 각 pixel이 변수가 된다 |
컴퓨터가 이미지를 인식하는 방법
=그림을 숫자로 변환해서 인식한다
=28*28 pixel 의 이미지는 총 784 (28*28) 개의 변수를 가진다
=MNIST 에서는 Multiple Regression을 이용해서 0~9까지 분류한다
=Machine Learning 에서 지도학습 분야에 해당한다(목적변수가 있다)
**추가 지식**
|
binomial Logistic Regression 결과값이 2개 (0,1)가 나온다, 이벤트의 발생을 1로 지정해서 특정 이벤트의 발생 여부를 확인 sigmoid 라고 부른다(y값이 0과 1사이의 값을 가지면서 s자 형태로 그려지는 함수, 가중치 w와 편향b (bias)를 구한다 |
숫자인식 시스템의 실습 = Keras 활용
|
Keras =사용자 친화적으로 개발되어 로밍을 최소화하고 최대의 효과를 낸다 =Tensorflow 위에서 동작하는 라이브러리 =단순신경망 구성에 좋다 |
숫자인식 코딩 방법
|
쥬피터 노트북에서 tensorflow, keras를 import |
|
mnist 데이터 로드 (훈련/test 데이터 shapte확인) |
|
y값을 keras의 catrgory 10개를 onehot 벡터로 변환 ==해당 숫자 위치의 값만 1이고 나머지가 0인 벡터 |
|
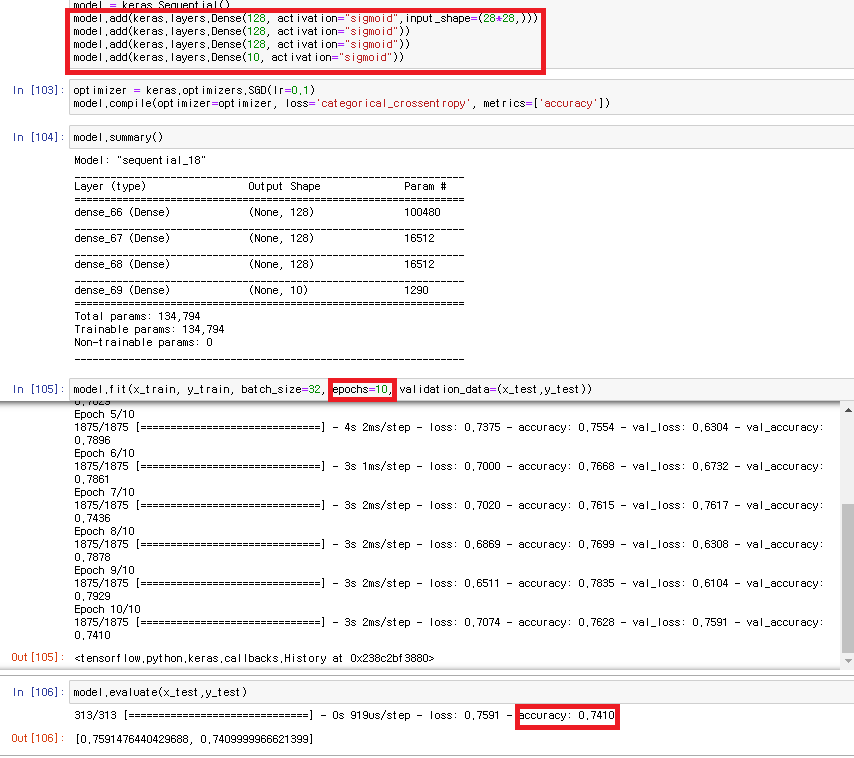
학습 모델의 제작 =레이어의 dense를 바꿔가며 학습 모델을 선정 =active function 은 sigmoid =Optimizer를 통한 학습 ***레이어를 추가한다 – keras의 dense부분 추가, 코드 라인을 더하는게 layer를 추가하는 것 |
|
결과보기 model.summary() |
|
****무조건 layer를 추가하는 것이 정확도를 올리는게 아니다*** |
실습화면














Quiz
|
수업 파일을 참고해서 layer를 추가 변경해서 정확도가 변경되는지 확인한다 |
|
model의 숫자를 변경, layer를 추가한다 작동횟수(epochs부분)을 바꾸어 accuracy 가 바뀌는지 확인한다 |
f-1 = dense
128,128,128,128,128,10 , epochs=11 , accuracy=0.7011
f-2 = dense
128,128,128,10 , epochs=10 , accuracy=0.7410
f-3 = dense
128,128,128,10,128,128,10 epochs=3 , accuracy=0.1135


댓글 없음:
댓글 쓰기