|
종류 |
특징 |
|
ANN |
=입력데이터의 구조를 고려하지 않아서 공간구조 데이터 처리에 나쁘다 |
|
DMLP |
=Fully Connected – 완전연결 구조로 높은 복잡도를
가지고 학습이 느리며 과적합 우려가 높다 |
|
CNN |
=컨볼루션 연산을 이용한 부분연결(최소 연결)로 수용장(Receptive
field) 가 있음 =입력Sample 의
크기가 달라도 처리가 가능하다 =컨볼루션, 풀링층이
번갈아가며 존재한다 |
|
DMLP |
=부분연결(Partially
connected) = n개의 node가 set을
이룬다=수용장 =총연결개수 = 수용장
개수 * 다음층의 노드개수 =DMLP의 입력 SAMPLE은
항상 같은 크기를 가져야 한다 ==pixel 의 수가 변하면 안된다 |
컨볼루션 연산
=해당 연산끼리 곱하고 더한것과 같다
=입력->커널,필터,윈도우(호칭은 다를수있다)->출력,특징맵(feature map)
=해당 연산끼리 곱하고 더한것과 같다
=입력->커널,필터,윈도우(호칭은 다를수있다)->출력,특징맵(feature map)

패딩(Padding)
=가장자리에 덧대어 크기가 줄어드는 것 방지
=양끝에 0을 추가 복사해서 과적합(overfitting)을 방지한다
=가장자리에 덧대어 크기가 줄어드는 것 방지
=양끝에 0을 추가 복사해서 과적합(overfitting)을 방지한다

절편(Bias)
=모든 칸에 다 있음,커널의 맨 앞에 추가해서 사용한다
=Transpose 시에는 가로로 변화도 가능하다
스트라이드(Stride)
=입력된 데이터에서 필터를 곱하는데 왼쪽부터 이동해 얼마나 이동할지 정하는 간격
=모든 칸에 다 있음,커널의 맨 앞에 추가해서 사용한다
=Transpose 시에는 가로로 변화도 가능하다
스트라이드(Stride)
=입력된 데이터에서 필터를 곱하는데 왼쪽부터 이동해 얼마나 이동할지 정하는 간격
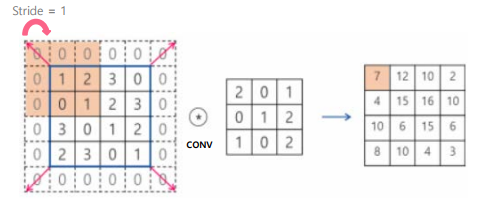
필터(Filter) 커널 추정
=특징이 data에 존재하는지 정의하는 것, 다수의 filter도 적용 가능함
=형태를 격자에 나타내서 표시한다

가중치 공유(weight sharing) 묶인 가중치(tied weight)
=입력계층에 적용되는 커널은 모두 동일한 set을 적용한다
=커널은 여러개 적용 가능하다
CNN의 특징
=이동에 동변(신호가 이동시그대로 특징맵에 반영된다(영상인식에서 물체 이동이나 음성인식에서 발음 지연에 효과적으로 대처한다
동변 vs 불변
=연산의 결과는 동변
=최종 인식은 불변
특징학습
=커널을 사람이 아닌 기계가
=표기시
 로 표기(k번째 커널의 i번째 매개변수라는 뜻)
로 표기(k번째 커널의 i번째 매개변수라는 뜻)=CNN도 DMLP 처럼 역전파로 학습한다
=커널은 학습(추정) 해야할 가중치 매개변수와 동일하다
Stride에서 크기가 바뀌는 규칙
=Stride가 k면 k 마다 하나씩 샘플링 해서 적용
=2차원 영상의 경우 특징맵이 로 작아진다
로 작아진다
Tensor(컬러이미지)에도 적용
=컬러영상, 이미지는 rgb라는 3개의 채널을 가진다
로 작아진다Tensor(컬러이미지)에도 적용
=컬러영상, 이미지는 rgb라는 3개의 채널을 가진다
=연산의 결과는 1개의 단일값이 나와서 feature map에 적용된다
3차원 구조데이터 적용
3차원 구조데이터 적용

=차원(dimension)이 증가해도 단일값을 도출한다
=입력데이터와 커널의 채널수는 동일해야 한다
=커널은 정방행렬이여야 한다
Tensor로 표시하는 데이터의 특징
=동영상 data
=시간에 따라 화소를 차지하는 물체가 달라지므로 최소값은 꾸준히 변함
=컬러 동영상의 차원 = 3 * s * 가로pixel * 세로pixel = tensor 크기
=MRI 영상 차원(Dimension - 흑백) = 1 * s * 가로pixel * 세로pixel = tensor 크기
==컬러는 rgb라 3을 흑백은 1을 곱하는 것
빌딩블록
=CNN도 DMLP와 같이 여러 층을 이어붙혀 깊은 구조를 만들수 있다
=주로 활성화 함수(Activation Function)은 Relu 함수를 사용하고 풀링 연산을 사용한다
풀링연산
=컨볼루션 layer 다음에 적용(컨볼루션 layer결과에 relu같은 활성화 함수 적용후 풀링적용)
=결과의 noise를 제거해준다
=결과를 요약하기 때문에 메모리 효율에도 기여한다
=상세 내용에서 요약통계를 추출한다
=매개변수가 없고 특징맵의 수를 그대로 유지
=max 풀링시 물체 인식이나 영상 검색에 효과적이다
=출력 data의 크기를 조절하는 기능
=입력데이터와 커널의 채널수는 동일해야 한다
=커널은 정방행렬이여야 한다
Tensor로 표시하는 데이터의 특징
=동영상 data
=시간에 따라 화소를 차지하는 물체가 달라지므로 최소값은 꾸준히 변함
=컬러 동영상의 차원 = 3 * s * 가로pixel * 세로pixel = tensor 크기
=MRI 영상 차원(Dimension - 흑백) = 1 * s * 가로pixel * 세로pixel = tensor 크기
==컬러는 rgb라 3을 흑백은 1을 곱하는 것
빌딩블록
=CNN도 DMLP와 같이 여러 층을 이어붙혀 깊은 구조를 만들수 있다
=주로 활성화 함수(Activation Function)은 Relu 함수를 사용하고 풀링 연산을 사용한다
풀링연산
=컨볼루션 layer 다음에 적용(컨볼루션 layer결과에 relu같은 활성화 함수 적용후 풀링적용)
=결과의 noise를 제거해준다
=결과를 요약하기 때문에 메모리 효율에도 기여한다
=상세 내용에서 요약통계를 추출한다
=매개변수가 없고 특징맵의 수를 그대로 유지
=max 풀링시 물체 인식이나 영상 검색에 효과적이다
=출력 data의 크기를 조절하는 기능

=각 sector에서 가장 큰 값을 선정해서 출력한다
댓글 없음:
댓글 쓰기