=기계학습 역사에서 가장 오래된 학습모델
=1950년->퍼셉트론->1980년대 다중 퍼셉트론(Multi level Perceptron)
퍼셉트론의 한계
=XOR문제의 해결 불가 문제
=1990년대에는 SVM 모델에 밀리는 형국
신경망
|
신경망 |
모델 |
=Feed forward – perceptron =Multi Level Perceptron =Deep Multi level Perceptron |
|
|
깊이 |
=얕은 신경망 (Hidden layer 1~2개) =깊은 신경망 (Hidden Layer 2~3개이상) |
|
|
논리 |
=결정론(deterministic)
– 입력과 출력의 개수가 같다-RBM,DBM을 제외한 모든것 =확률론적(Stochastic)
- d입력수와 출력의 수가 다르다 –RBM,DBM 방식, 유사한 패턴을 ‘생성’ 할수
있다 |
|
Perceptron |
특징 |
=입력과 출력층을 가진다( 입력층은
연산을 안하기 때문에 count하지 않는다) =d개의 노드를 가지는 입력층의 i번째 노드는 특징벡터의 요소 xi다 =항상 1이되는 bias (절편) 노드는 x0=1 =출력은 1개 =가중치(weight)는
d+1개 |
|
|
동작 |
=입력층에 값이 들어오면 입력층에 해당하는 가중치 w와 곱한 결과를 모두 더해 s를 구하고 활성화 함수(Activation Function)을 적용 |
|
|
특징 |
=그래프상에서 독립변수의 개수가 3개 이상은 초평면(Hyper plain) 이라고 함 |
|
|
핵심 |
=그래프의 가중치(weight)를
찾는 것 =And OR 게이트 에서는 x(독립변수)가 2개뿐이였지만 현실에선? -
d차원공간, 수만개의 sample 에서 어떻게
학습 할 것인가? =최적의 목적함수를 찾기 위한 조건 J(w)=0 이 되게한다 =w가 최적이면 모든 샘플을 다 맞추면 J(w)=0이된다 =틀리는 샘플이 많은 w일수록
J(w)가 커지는것 =그라디언트 calculate 경사하강법을
사용 |
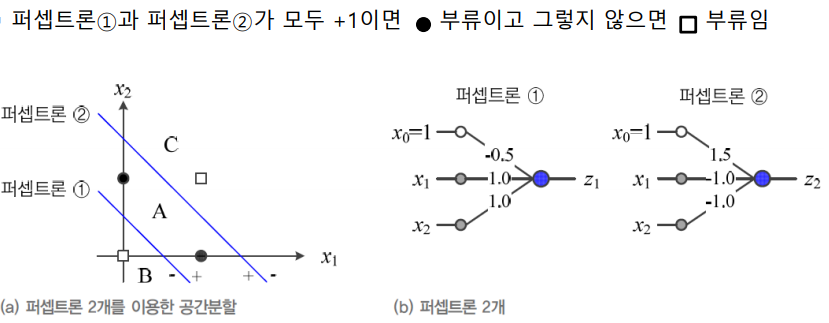
다중 퍼셉트론(MultiLayer Perceptron)
=퍼셉트론은 선형(Linear) 분류하는데 한계가 있다 –XOR 을 구분할수 없음

=은닉층(Hidden Layer)를 둔다
=Sigmoid function(s형태의 함수 라는뜻) 을 사용한다
==계단함수보다 부드러운 형태

공간 분리의 soft hard 함수 분류
=hard – step(계단)함수
=soft - sigmoid, hyperbolic tangent – 모든 구간의 미분이 가능하다, 속도가 빠르다
Deep learning 의 특징
=logistic 이나 hyperbolic tangent를 많이 사용하면 종국에는 값이 0이된다, 이때 Relu 함수를 사용해서 이를 해결한다
Hyper parameter
=신결망 설계시 사용자가 지정하는 매게변수
Layer의 개수
=입력층은 count 하지않는다
=은닉층의 은닉 node를 몇 개로 할것인가가 중요, P가 너무크면 과적합, 작으면 과소적합
Layer에서 가중치 계수 확인

은닉층은 특징벡터를 분류에 유리한 특징 공간으로 변화하는 것
=feature extractor 가능
오류의 역전파 알고리즘
=error back propagarion algorithm
훈련집합=특징
|
훈련집합 |
특징벡터, 분류벡터로 분류, 분류벡터 표기-one-hot-code 사용하는 함수(step,sigmoid 등등)에 따라 0,-1 등이 다르다 |
|
|
기호표기 방식  |
|
기계학습의 목표 |
모든 sample을 옳게 분류하는 함수를 찾는다 |
|
가중치 업데이트 방식 |
온라인(stochastic), 배치 방식이 있고 미분의 용의성을
위해 앞에 1/2를 곱해준다 |
Mini-batch 방식
=효율적 연산을 위해 이전단계 값을 저장해서 사용한다
=순서를 섞기 때문에 sample 마다 빈도가 달라질수 있다
=batch와 스토캐스틱의 중간방식
=1회에 사용하는 sample 의 수를 저장해서 사용
=현대 기계학습의 중점기술
휴리스틱 알고리즘
=순수한 최적화 알고리즘으로는 높은 성능이 나오지 않는다
==원인=데이터 희소성,노이즈,잘못된 모델링
=학습을 이용해서 성능을 올린다, end-to-end 방식 사용
댓글 없음:
댓글 쓰기