=데이터를 원하는 형태로 변형, 분석에 적합한 형태로 가공하는 작업
=동일 용어- 데이터 가공, 랭글링, 머징
사용 R package
=dplyr
=데이터 처리에 특화된 R패키지,
=Data frame 처리하는 함수 집합
=”쉽게 하는 r데이터 분석” 참고
R 파이프 연산자
|
동치 조건등을 필터링 할 때 사용하는 것 |
| %>% (ctrl + shift + m)입력 |
| magrittr 또는 dplyr 패키지를 설치하고 로딩하면 됨 dplyr (디플라이어)가 짧고 범용적이니까 dplyr 를 기억해두자. 실제 %>% 연산자(함수)를 제공하는 패키지는 magrittr인데 dplyr를 로드(또는 설치)할 때 같이 된다. install.packages("magrittr") library(magrittr) install.packages("dplyr") library(dplyr) 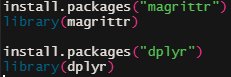 |
| 패키지를 사용하지 않으면 이렇게 나온다 |
R실습
데이터 요약하기
| CSV 파일 읽기 |
| exam <- read.csv("D:/OneDrive/### Working/csv_exam.csv") |
 |
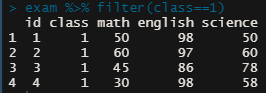
| exam 에서 CLASS 가 1인 경우만 추출 |
| exam %>% filter(class==1) |
 |
| exam 에서 CLASS 가 2인 경우만 추출 |
| exam %>% filter(class==2) |
 |
| exam 에서 CLASS 가 1이 아닌 경우만 추출 |
| exam %>% filter(class!=1) |
 |
| 수학 점수가 60점을 초과한 경우 추출 |
| exam %>% filter(math > 60) |
 |
| 영어 점수가 90점 이하인 경우 추출 |
| exam %>% filter(english <= 90) |
 |
| CLASS 가 1,3,5 인 경우 추출 ( %in% in 기호와 c() 함수 사용) |
| exam %>% filter(class ==1 | class ==3 | class==5) exam %>% filter(class %in% c(1,3,5)) |
 |
| CLASS 가 1,2인 ROW를 추출해 평균 구하기 |
| class1 <- exam %>% filter(class ==1) class2 <- exam %>% filter(class ==2) mean(class1$math) mean(class2$math) |
 |
| Select() 를 사용해 변수중 일부만 추출하기 |
| exam %>% select(math) #math 추출 exam %>% select(english) #english 추출 exam %>% select(-math) #math 제외 exam %>% select(-math,-english) #math, english 제외 |
| Arrange 함수를 사용한 데이터의 오름/내림 차순 정렬 |
| exam %>% arrange(math) #math 오름차순 정렬 exam %>% arrange(desc(math)) #math 내림차순 정렬 exam %>% arrange(class,math) #class와 math 를 오름차순 정렬 |
| 데이터의 파생변수 생성하기-1 |
| exam %>% mutate( total = math + english + science) |
 |
| 데이터의 파생변수 생성하기-2 |
| exam %>% mutate( total = math + english + science, mean =(math+english+science)/3 ) |
 |
| 데이터의 파생변수 생성하기-3-조건 달아서 pass,fail 확인 |
| exam %>% mutate( test=ifelse(science >=60,"pass","fail") ) |
 |
| 집단별 요약하기 – summarise() |
| exam %>% summarise(mean_math = mean(math)) |
 |
| 집단별 요약하기 – grooup_by |
| exam %>% group_by(class) %>% summarise(mean_math = mean(math)) == A tibble : 5x2 데이터가 5행 2열 tibble 은 데이터 프레임에서 기능이 추가된 것 == int : 정수 , dbl : 소수점이 있는 숫자(double,부동 소수점 |
 |
| 집단별 요약한 값의 추출 |
| exam %>% group_by(class) %>% summarise(mean_math = mean(math), sum_math = sum(math), median_math = median(math), n = n()) ==n() 은 데이터의 행으로 되어 있는지 빈도를 물어보는 기능으로 그룹으로 나누어 반별 학생빈도 추출 |
 |
데이터 요약하기
| Ggplot2의 mpg 데이터셋 사용 |
| install.packages("ggplot2") library(ggplot2) mpg %>% group_by(manufacturer, drv) %>% summarise(mean_cty = mean(cty)) |
| mpg데이터를 이용 하위 집단 별 평균 구하기 회사별로 집단을 나누고 다시 구동방식을 나눠 연비 산출하기 |
| mpg %>% group_by(manufacturer, drv) %>% summarise(mean_cty = mean(cty)) |
 |
| mpg데이터에서 회사-suv-통합연비-통합연비 평균을 내림차순으로 상위 5개 출력 |
| mpg %>% group_by(manufacturer) %>% filter(class=="suv") %>% mutate(tot=(cty+hwy)/2) %>% summarise(mean_tot = mean(tot)) %>% arrange(desc(mean_tot)) %>% head(5) |
 |
데이터 합치기
인공지능
인공지능 시대의 생존 전략
국내 ai 기업의 특징
=보통 어떤걸 원하는지 기업 자체도 잘 모르고 AI, AI 등을 외치는 경우가 많음
시각화 방법중 쉽게 접근 가능한 방법 소개
=SOME.CO.KR
=빅카인즈(https://www.kinds.or.kr/)
=워드 클라우드 생성기 사이트 등
| 중간/기말 고사 점수 임의 생성 & 확인 |
| #중간고사 데이터 생성 test1 <- data.frame(id=c(1,2,3,4,5),midterm = c(60,80,70,90,85)) #기말고사 데이터 생성 test2 <- data.frame(id=c(1,2,3,4,5), final=c(70,83,65,95,80)) |
 |
| 생성된 데이터에서 id를 기준으로 합쳐서total 에 할당 |
| Left_join 을 활용한 가로 총합 |
| total <-left_join(test1,test2, by="id") |
 |
| 데이터 생성 |
| #학생 1~5번까지 데이터 생성 group_a <-data.frame(id=c(1,2,3,4,5),test=c(60,80,70,90,85)) #학생 6~10번까지 데이터 생성 group_b <-data.frame(id=c(6,7,8,9,10),test=c(70,83,65,95,80)) |
 |
| Bind_rows 를 이용한 데이터 세로 합치기 |
| group_all <-bind_rows(group_a,group_b) |
 |
| Column 개수가 안맞을 때 데이터 합치기 상황 |
| #학생 1~5번까지 데이터 생성 group_a <-data.frame(id=c(1,2,3,4,5),test=c(60,80,70,90,85)) #학생 6~10번까지 데이터 생성 group_b <-data.frame(id=c(6,7,8,9,10),test=c(70,83,65,95,80)) #학생 11~13번까지 데이터 생성 group_c <-data.frame(id=c(11,12,13),test_1=c(10,20,30),test_2=c(40,50,60)) |
 |
인공지능
| 정의 | 인지, 학습등 인간의 지적 능력의 일부, 또는 전체를 컴퓨터로 이용해 구현하는 것 |
| 파급효과 | 금융&보험 일자리의 81.8%가 사라질 위기 사람이 로봇을 관리하고 제어하는 방향의 노동시장의 성장 |
| 수준 | Level 1~4까지의 단계 |
인공지능 시대의 생존 전략
| 반복적인 작업을 하는 직업의 소멸 | 미국의 실리콘벨리의 인재상 |
| 머신러닝,통계전문 프로그래밍, 확률, 통계, 선형대수, 수학적 최적화 | |
| 프로그래밍 스킬=r,python,c,c++,java,tensorflow의 이해 | |
| 팀워크=여러 개의 팀을 구성해 실제 개발 수행팀을 짜고 결과를 통합하는 능력 |
국내 ai 기업의 특징
=보통 어떤걸 원하는지 기업 자체도 잘 모르고 AI, AI 등을 외치는 경우가 많음
시각화 방법중 쉽게 접근 가능한 방법 소개
=SOME.CO.KR
=빅카인즈(https://www.kinds.or.kr/)
=워드 클라우드 생성기 사이트 등
댓글 없음:
댓글 쓰기