=다른 분류에 속하는 데이터간 간격(마진)이 최대가 되는선을 찾아서 데이터를 분류하는 모델

인공지능과 Bigdata 의 연관성
=예측, 분류는 지도학습의 밀접한 관계
=인공지능과 bigdata는 같이 학습이 진행되야 하는 것
|
SVM 의 활용 & 특징 |
=유전자 DATA의 분류 =언어식별 =보안결함 =이상치 거래 탐색 =과적합이 잘 일어나지 않는다 |
|
비선형 상태의 SVM |
|
|
1차원 DATA |
분류되지 않는다 |
|
2차원상 DATA |
분류가능 – 선형적으로 분리되게 만들어준다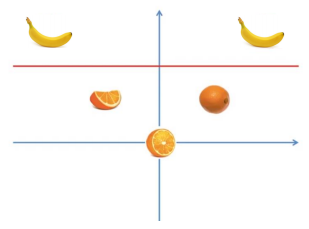
|
과적합 이란?
=많은 횟수의 학습으로 인해 실제 평가에서는 효율이 떨어지는 것
커널트릭
=선형으로 분류가 불가능할 때 차원을 증가시켜서 분류를 용이하게 하는 방법
수업중 소개된 관련 논문 제목
=SVM을 활용한 패턴인식 기법 – 신장범
=판별분석,인공신경망, SVM을 이용한 수익율 성능 비교 연구
데이터 분석 방법론 소개
|
KDD |
Knowledge Discovery Databases |
|
1.데이터셋 선택(Selection_) |
|
|
2.데이터 전처리 (preprocessing) |
노이즈, 이상값, 결측치 제거 |
|
3.데이터 변환 (Transformation) |
변수 탐색, 차원축소 |
|
4.데이터 마이닝 (Data
Mining) |
목적에 맞는 마이닝 기법 선택 |
|
5.데이터 마이닝 결과 평가 (Interpretation
/ Evaluation) |
해석 / 평가 |
| 데이터마이닝, 기계학습, 인공지능, 패턴인식 , 데이터 시각화에 사용 | |
|
CRISP_DM |
Cross Industry Standard Process for Data Mining |
|
1.Business Understanding |
업무 목표 수립 현재 상황 평가 마이닝 목표 수립 프로젝트 계획 수립 |
|
2.Data understanding |
초기 데이터 수집 데이터 기술(Discriminate) / 탐색 데이터 품질 검증 |
|
3.Data Preparation |
데이터 설정 / 선택 / 정제 / 생성 / 통합 / 형식 적용 |
|
4.Dmodeling |
모델링 기법 선택 테스트 설계 생성 모델 생성 / 평가 |
|
5.Evaluation |
결과 평가 프로세스 재검토 향후 단계 설정 |
|
6.Deployment |
전개 계획 수립 모니터링 / 유지보수 계획 수립 최종 보고서 작성 프로젝트 재검토 |
SVM 실습 in R
| Source Code |
| # svm (Support Vector Machine) install.packages("e1071") library(e1071) data(iris) samp <- c( sample(1:50,35), sample(51:100,35), sample(101:150,35)) iris.tr <-iris[samp,] iris.te <- iris[-samp,] m1 <- svm(Species~., data = iris.tr, kernel="linear") m2 <- svm(Species~., data = iris.tr, kernel="polynomial") m3 <- svm(Species~., data = iris.tr, kernel="radial") x <- subset(iris.te, selec=-Species) y <- iris.te$Species pred1 <- predict(m1, x) pred2 <- predict(m2, x) pred3 <- predict(m3, x) table(y, pred1) table(y, pred2) table(y, pred3) |
| Result |
> table(y, pred1) pred1 y setosa versicolor virginica
setosa 15 0 0
versicolor 0 15 0
virginica 0 0 15 > table(y, pred2) pred2 y setosa versicolor virginica
setosa 15 0 0
versicolor 0 15 0
virginica 0 7 8 > table(y, pred3) pred3 y setosa versicolor virginica
setosa 15 0 0
versicolor 0 15 0 virginica 0 2 13 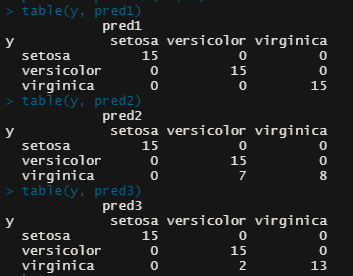 |
| Linear SVM = 데이터를 선형으로 분리하는 최적의 선형 경계를 찾아주는 알고리즘Radial SVM = 주어진 데이터를 구차원 특징 공간으로 이동시켜주는 것 , 원래 차원에서 보이지 않던 선형으로 분리해 줌 Polynomial SVM = 차수가 n인 다항식들이 관련되는 더 높은 차원에서의 서포트 벡터 머신 |
댓글 없음:
댓글 쓰기