=내용 제거
=내용 제거
CNN (Convolution Neural Network)
| 이미지 처리에 뛰어난 성능이 나옴 |
| 합성곱(Convolution Layer)와 풀링층(Pooling layer)로 구성 =합성곱 =합성곱 연산, 합성곱 연산의 결과가 RELU 함수를 지나감 =풀링층 =합성곱층 이후 Pool 이라는 구간을 지나 풀링 연산이 일어남 |
| 합성곱 신경망의 특징맵 =입력값에서(커널(필터)) 값을 씌워서 사용한다 |
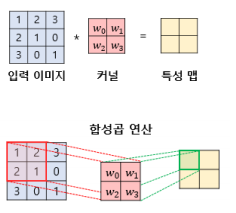
| 이미지를 1차원 벡터로 변환한다 =그림 자체는 사람이 이해하기 좋으나 계산에는 용이하지 않기 때문에 가로로 변환한다 =나눠진 구역이 모두 변수가 되고 색상이 변한 부분이 중요 변수가 된다  =커널, 필터 라는 n*m 크기의 겹처지는 부분의 이미지와 채널의 원소의 값을 곱해서 모두 더한 값을 출력한다 =필터의 숫자대로 변수가 급격히 증가한다  |
=커널의 이동거리를 사용자가 지정하고 이동한 범위를 말함
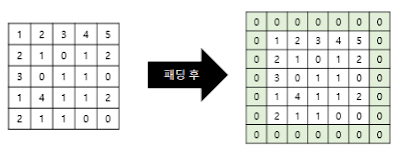
=합성곱 연산전 입력의 가장자리에 지정 개수의 폭만큼 행과 열을 추가
=원본에 필터를 적용시 자꾸 이미지 크기가 줄어드는 것 방지
합성곱 신경망의 가중치
=3*3 이미지를 처리한다고 가정
=이미지를 1차원으로 정렬
=은닉층에 4개의 뉴런을 지정한다
=각 이미지 cell은 은닉층에 값을 곱한다

스트라이드 연산 재현
=입력 이미지와 커널을 연산해 특징맵을 만들어낸다

=CNN에서 편향(절편, bias) 적용 역시 가능
=bias사용시 모든 커널을 적용한 뒤에 더해진다
=값은 하나만 존재하고 커널이 적용된 결과의 모든 원소에 더해진다

풀링(Pooling)
=합성곱층( 합성곱 연산 + 활성화함수) 다음에 풀링층을 추가 하는 것이 일반적
=일반적으로 최대 풀링(max pooling) 과 평균 풀링(average pooling) 이 사용
=특성맵을 다운샘플링해서 줄이는 과정
=스트라이드가 2일 때 2*2크기로 max pooling 시 특성맵이 절반으로 줄어든다
=max pooling – 커널과 겹치는곳 안에서 최대값을 추출하는 방식
=average pooling – 평균값 추출
=합성곱과 비슷하나 가중치가 없고 맵의 크기가 줄어들어 가중치 개수가 줄어든다
실습
==Tensorflow 를 사용해 연비를 예측해본다(Regression 사용)
| #산점도를 그리기 위한 seaborn 패키지 설치 !pip install -q seaborn |
| from __future__ import absolute_import, division, print_function, unicode_literals, unicode_literals import pathlib import matplotlib.pyplot as plt import pandas as pd import seaborn as sns import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers print(tf.__version__) |
 |
| #Auto MPG 데이터셋 구하기 dataset_path = keras.utils.get_file("auto-mpg.data","http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data") dataset_path |
|
|
| #pandas 를 사용해 데이터 읽기 column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight','Acceleration','Model Year','Origin'] raw_dataset = pd.read_csv(dataset_path,names=column_names,na_values="?",comment="\t",sep=" ",skipinitialspace=True) dataset = raw_dataset.copy() dataset.tail() |
 |
| #데이터 정제하기, 데이터셋은 일부 누락되어있는 상태임 dataset.isna().sum() |
 |
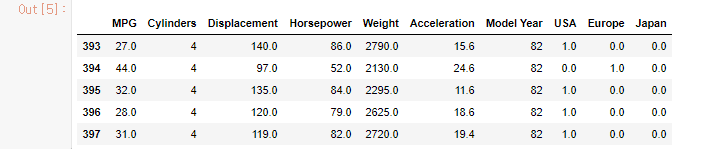
| #누락된 행을 삭제 dataset = dataset.dropna() #"Origin"열은 수치형이 아니고 범주형이기 때문에 one-hot encoding으로 변환 origin = dataset.pop('Origin') dataset['USA']=(origin==1)*1.0 dataset['Europe']=(origin==2)*1.0 dataset['Japan']=(origin==3)*1.0 dataset.tail() |
 |
| #데이터 셋을 training 셋과 test 셋으로 분할하기 #test 셋은 모델의 최종 평가에서 사용 train_dataset = dataset.sample(frac=0.8,random_state=0) test_dataset = dataset.drop(train_dataset.index) |
| #훈련 셋에서 몇개의 열을 선택해 산점도 행렬을 지정 sns.pairplot(train_dataset[["MPG","Cylinders","Displacement","Weight"]],diag_kind="kde") |
 |
| #전반적 통계 확인 train_stats = train_dataset.describe() train_stats.pop("MPG") train_stats=train_stats.transpose() train_stats |
 |
| #특성과 레이블 분리하기 #특성에서 타깃값 또는 레이블을 분리 train_labels = train_dataset.pop('MPG') test_labels = test_dataset.pop('MPG') |
| #데이터 정규화, train_stats 통계를 보고 각 특성의 범위가 얼마나 다른지 확인 #특성의 스케일과 범위가 다르면 정규화(normalization) 하는것이 권장 #훈련시키기 어렵고 입력단위에 의존적 모델이 만들어짐 #의도적으로 훈련셋만 사용하고 통계치를 생성 #이 통계는 테스트세트 정규화에도 사용 def norm(x): return (x - train_stats['mean']) / train_stats['std'] normed_train_data = norm(train_dataset) normed_test_data = norm(test_dataset) |
| #모델 만들기 #2개의 완전연결 은닉층을 사용 모델을 만듦 #출력층은 하나의 연속적 값을 반환 #나중에 두 번째 모델을 만들기 쉽도록 build_model 함수로 모델 구성 단계를 감싸준다 def
build_model(): model = keras.Sequential([ layers.Dense(64,
activation='relu',input_shape=[len(train_dataset.keys())]), layers.Dense(64, activation='relu'), layers.Dense(1) ]) model.compile(loss='mse', optimizer=optimizer,metrics=['mae','mse']) return model |
| #모델 확인(summary 메소드를 사용해서 정보 출력) model = build_model() model.summary() |
 |
| #모델을 한번 실행, 훈련 세트에서 10 샘플을 하나의 배치로 만들어 model.predict 메서드 호출 #flot32 는 32비트 flot64는 64비트를 사용하는것, #float64의 메모리 사용량이 두배라는것 #훨씬 정확한 숫자와 더 많은 숫자를 저장 가능 example_batch = normed_train_data[:10] example_result = model.predict(example_batch) example_result |
 |
| #모델 훈련과정 #1000번의 epoch 동안 훈련 #1 epoch 가 끝날때마다 점(.)을 출력해 진행과정 표시 class
PrintDot(keras.callbacks.Callback): def on_epoch_end(self, epoch, logs): if epoch % 100 == 0: print('') print('.',end='') EPOCHS = 1000 history = model.fit(normed_train_data, train_labels,epochs=EPOCHS, validation_split = 0.2, verbose=0,callbacks=[PrintDot()]) |
 |
| #history 객체에 저장된 통계치를 사용해 모델의 훈련과정 시각화 hist = pd.DataFrame(history.history) hist['epoch'] = history.epoch hist.tail() |
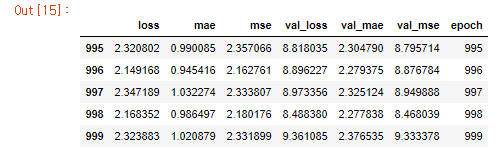 |
| import matplotlib.pyplot as plt def
plot_history(history): hist = pd.DataFrame(history.history) hist['epoch']= history.epoch plt.figure(figsize=(8,12)) plt.subplot(2,1,1) plt.xlabel('Epoch') plt.ylabel('Mean Abs Error [MPG]')
plt.plot(hist['epoch'],hist['mae'],label='TrainError')
plt.plot(hist['epoch'],hist['val_mae'],label='Val Error') plt.ylim([0,5]) plt.legend() plt.subplot(2,1,2) plt.xlabel('Epoch') plt.ylabel('Mean Square Error [$MPG^2$]')
plt.plot(hist['epoch'],hist['mse'],label='TrainError')
plt.plot(hist['epoch'],hist['val_mse'],label='Val Error') plt.ylim([0,20]) plt.legend() plt.show() plot_history(history) |
 |
| #그래프를 보면 수 백번 에포크를 진행한 이후 모델이 거의 향상되지 않는다 #model.fit 메소드를 수정해 검증 점수가 향상되지 않으면 강제 정지 #에포크마다 상태점검을 위한 callback 적용 #지정 에포크동안 성능향상이 없으면 훈련이 멈춘다 model = build_model() #patience 매개변수는 성능 향상 체크할 에포크 횟수 early_stop = keras.callbacks.EarlyStopping(monitor='val_loss',patience=10) history = model.fit(normed_train_data, train_labels, epochs=EPOCHS, validataion_split = 0.2, verbose=0, callbacks=[early_stop,PrintDot()]) plot_history(history) |
 |
| #모델을 훈련시 사용하지 않았던 테스트 세트에서 모델 성능 확인 #이를 통해 모델이 실전 투입시 모델의 성능을 짐작 가능 loss, mae, mse = model.evaluate(normed_test_data, test_labels, verbose=2) print("테스트 세트의 평균 절대 오차: {:5.2f} MPG".format(mae)) |
 |
| #예측 마지막으로 테스트 세트에 있는 샘플을 사용해 MPG값을 예측 test_predictions = model.predict(normed_test_data).flatten() plt.scatter(test_labels, test_predictions) plt.xlabel('True Values [MPG]') plt.ylabel('Predictions [MPG]') plt.axis('equal') plt.axis('square') plt.xlim([0,plt.xlim()[1]]) plt.ylim([0,plt.ylim()[1]]) _=plt.plot([-100,100],[-100,100]) |
 |
| #오차분포 확인 error = test_predictions - test_labels plt.hist(error,bins=25) plt.xlabel("Prediction Error [MPG]") _=plt.ylabel("Count") |
 |
댓글 없음:
댓글 쓰기