이번장에서는, 물론 많은 알고리즘중 극히 일부에 해당하지만 많이 사용되는 그래프상에서 자주 사용하는 알고리즘에 대해서 살펴볼것이다.
2.6.1 그래프/트리에서 공통으로 사용하는것.
가장 많이 사용하는 알고리즘들을 예로 들면 그래프 탐색,트리,특별한 subgraph 같은 알고리즘이 있다.
소셜미디어를 생각하면 소셜미디어는 다수의 유저가 있다, 이때 사용자의 평균 나이를 계산하는 목적을 가지고 접근한다 생각해보자.
보통 사용하는 기술은 한명의 유저에서 시작해서 친구를 보고 친구의 친구를 탐색하는 방법을 취한다.
탐색기술은 2가지를 보장하는데 1.모든 유저를 탐색할수있다, 2.모든 유져는 1번이상 방문하지 않는다.
이장에서는, 두가지 탐색 알고리즘을 살펴보게 된다: depth-first search (DFS) --깊이 우선 탐색 기법--과 breadth-first search (BFS) --넓이 우선 탐색 기법--을 살펴보게 된다.
깊이 우선탐색 Depth-First Search (DFS)의 정의--이하 DFS로 표기한다--.
DFS 깊이 우선 탐색은 노드 Vi에서 시작하게된다, 다음으로 이웃노드를 선택해서 DFS알고리즘을 수행한 이후에 다음 노드를 방문하게 된다.
다르게 설명하면, DFS 는 뒤로 다시 돌아가기전에 최대한 깊게 먼저 탐색하는것이다.
노드 i가 j와 k를 이웃으로 가지고 있다고 가정할때.
깊이 우선 탐색은 시작할때 i에서 시작해, j를 다음으로 탐색한다,즉 노드 k를 탐색하기전 i와 j를 탐색하게 되는것이다.
다시 설명하면, 노드 k보다 j가 더 깊이 있는 상황이라면 j가 먼저 탐색되게된다.
깊이 우선 탐색은 트리와 그래프에서 공통적으로 사용될수 있다, 하지만 시각화에서 더 좋은 효과가 나기 위해서 트리가 더 효과가 좋다.
그림 2.19를 보면 트리에서 DFS를 수행한 상황을 확인할수 있다.
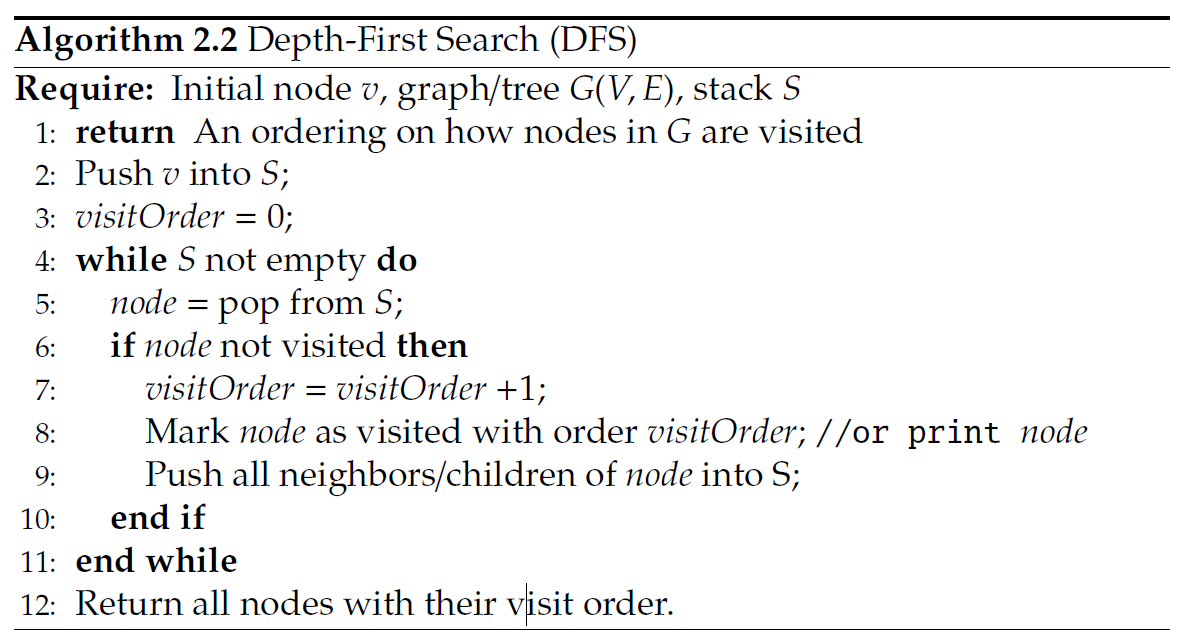
DFS알고리즘을 위의 Algorithm 2.2. 에서 볼수 있다.
알고리즘은 스텍구조에서 사용되는데 싶이 우선 탐색에서 탐색하지 않은 노드의 탐색에 효과가 좋다.
넓이 우선 탐색 Breadth-First Search (BFS) --이하 BFS로 기술--
BFS 를 시작하는 노드에서, 이웃 노드 먼저 탐색하고, 다음이웃 노드로 탐색하게 된다.
DFS처럼, 알고리즘은 트리와 그래프에서 주로 사용되면 도표 Algorithm 2.3 에서 확인 가능하다.
해당 알고리즘은 큐 구조에서 사용되며 넓이 탐색에 사용된다.
그림 2.19에서는 트리에서 해당 알고리즘이 수행된 상황을 보여준다.
소셜 네트워크에서, BFS와 DFS를 모두 사용가능한데, 알고리즘의 선택기준은 처음 방문할 노드의 선택에 따라 좌우된다.
소셜미디어에서, 가장 가까운 이웃을(친구같은)먼저 탐색하는게 중요하다, 그러므로 일반적으로 넓이우선 탐색이 더 자주 사용되게 된다.


그림 2.19 :그래프 탐색의 예시.

2.6.2 최소 경로 알고리즘의 정의.
다양한 시나리오에서, 두개의 노드간 최소의 비용을 산정하는 알고리즘은 언제나 중요하다.
예를들면, 네비게이션의 상황에서, 도시끼리 길로 연결되어 있는 가중치 네트워크가 있다고 생각해보자, 그리고 이때 목적지 도시로 이동하는 가장 최소의 비용의 경로를 찾는것이다.
소셜 미디어 마이닝에서, 그래프의 직경(diameter, 마이닝에서 직경이란 가장큰 가중치를 가지는 엣지에 결정됨)을 측정해 소셜네트워크가 얼마나 밀접하게 연결되어 있는지 결정하는게 매누 중요하다.
직경의 측정은 위에서 언급했든 그래프 상에서 사장긴 경로를 대상으로 한다.
다익스트라(Dijkstra) 알고리즘의 정의.
가장 잘 사용되는 최소 경로 알고리즘은 1959년 에츠허르 다익스트라가 정의한 알고리즘이다.
알고리즘은 가중치 그래프와 비-음수 엣지를 대상으로 설계되었다.
알고리즘은 가장 최소의 비용 경로를 탐색하는데 노드 s 에서 다른 노드로 가능 가장 적은 비용을 가지는 경로를 탐색 하는것이다.
다익스트라 알고리즘은 도표 Algorithm 2.4에 자세히 나와있다.
언급했듯이, 알고리즘의 목표는 그래프상에서 시작노드 s에서 다른노드로 이동하는 가장 최소 비용을 찾는것이다.
도표 Algorithm 2.4의 3번째 줄을 보면 지속적으로 최소의 비용 거리를 탐색하고 있다.
3번째 줄을 보면 알고리즘은 다음 노드에 대한 무한한 길이의 최단 경로가 있다고 가정한다, 그리고 탐색하면서 이것보다 작은 값을 가지는 거리 가중치에 대해서 지속적으로 업데이트 하게된다.

알고리즘의 단계는 다음과 같이 구성되어 있다:
1.모든 노드는 처음에 아무도 방문한적이 없다.
방문하지 않은 노드를 기점으로, 최소비용의 길이가 선택되게 된다.
그리고 알고리즘에서 가장 작은 경로로 저장해둔다.
2.이 노드에서, 아직 방문하지 않은 노드를 전수조사 하게 된다.
미 방문된 이웃들에서, 현재 저장해둔 경로(최소경로에 담겨있는값)에서 더 줄일수 있는지 확인하게 된다.
이건 다음과 같은 방식으로 비교 되는데, 현재 (저장된) 최소경로와 이웃 노드로 이동하는 비용을 비교하는 방식으로 비교하게 된다.
이건 알고리즘 Algorithm 2.4.png 에서 17번 line에서 수행하고있다.

노드 s와 t사이의 최소비용 거리 계산하는방법. 각 노드안에 있는 값은 해당 단계까지 계산된 가장 짧은 경로 거리값을 보여준다. 화살표는 노드 이동 분석이 완료됨을 나타낸다
3.현제 최단 경로가 더 좋아질수 있다면, 경로와 길이는 지속적으로 업데이트 된다.
경로는 수행 시퀀스에 따라 지속적으로 저장되게 된다.
모든 노드에 대해서, 이전에 방문했던 노드에 대한 정보를 저장할 필요가 있다, 따라서 배열에는 이동에 대한 추적 정보를 저장하게된다.
4.노드의 방문 이후에는 체크 되며 탐색은 더이상의 이웃이 없을때까지 진행되며, 1.끝나는 최단경로와 2.최단경로 길이는 변경되지 않는다.
단계를 좀더 확실히 학습하기 위해,다익스트라 알고리즘의 연습문제를 살펴보기를 권한다.
Example 2.3.그림 2.20을 보면 다익스트라 알고리즘의 예시를 볼수있다.
s에서 t까지 가는 최소비용 거리를 탐색하게 된다.
최소비용 경로는 점선으로 강조되어 있다.
연습해보면, 최소비용 거리는 배열에 의해 저장되고 있음을 볼수있다..

댓글 없음:
댓글 쓰기